Description
A Partitioned Data Storage component acts as a storage system for messages and binary data on the spacecraft. It acts as a ‘hard drive’ for log messages that can be connected to a Computer and the Telemetry System. The storage system is able to track data stored as bytes and return references to the data that can be read and written.
Example Use Cases
- Tracking message data over time.
- Storing raw binary data that can be read from the onboard computer.
- Receiving data from a ground station for later use.
Module Implementation
A partitioned data storage system is made up of a number of clusters. Each cluster is an individual data storage node. They have the following properties:
- Stores data in the form of bytes
- Have a fixed amount of data within the cluster
- Can be resized and data can be deleted
- Can return pointers to the particular data
Reading and writing data in clusters deal with pointers. A pointer will refer to the location within the storage system the data is written, along with the size of the bytes.
When writing to the storage system, the following process is followed in the code implementation:
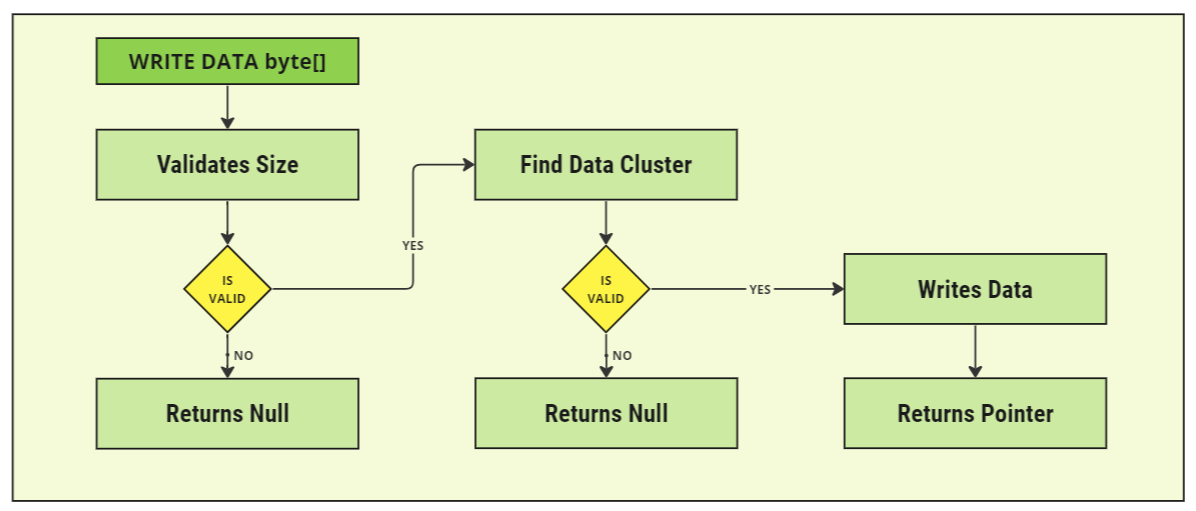
- Validates Size: The system checks if the size of the byte data exceeds the number of bytes within the chunk. If it does, then the storage system requires a larger chunk size for each cluster to store these messages.
- Finds Cluster: The system then looks through all available clusters, starting from the lowest index, to find a cluster that has enough data available to fit the new incoming data. If none exist, a new cluster will be created.
- Writes Data: The system then writes the data within the chunk, starting from the end of the previous data that is written, and inputs all bytes into the chunk for storage.
- Returns Pointer: Finally, a pointer that contains the information about where the data was written is returned. This ensures that when reading data, the correct location can be read.
When reading from the storage system, the user is required to pass in the appropriate pointer that was returned from the writing stage of the storage. The following process is followed in the code implementation:
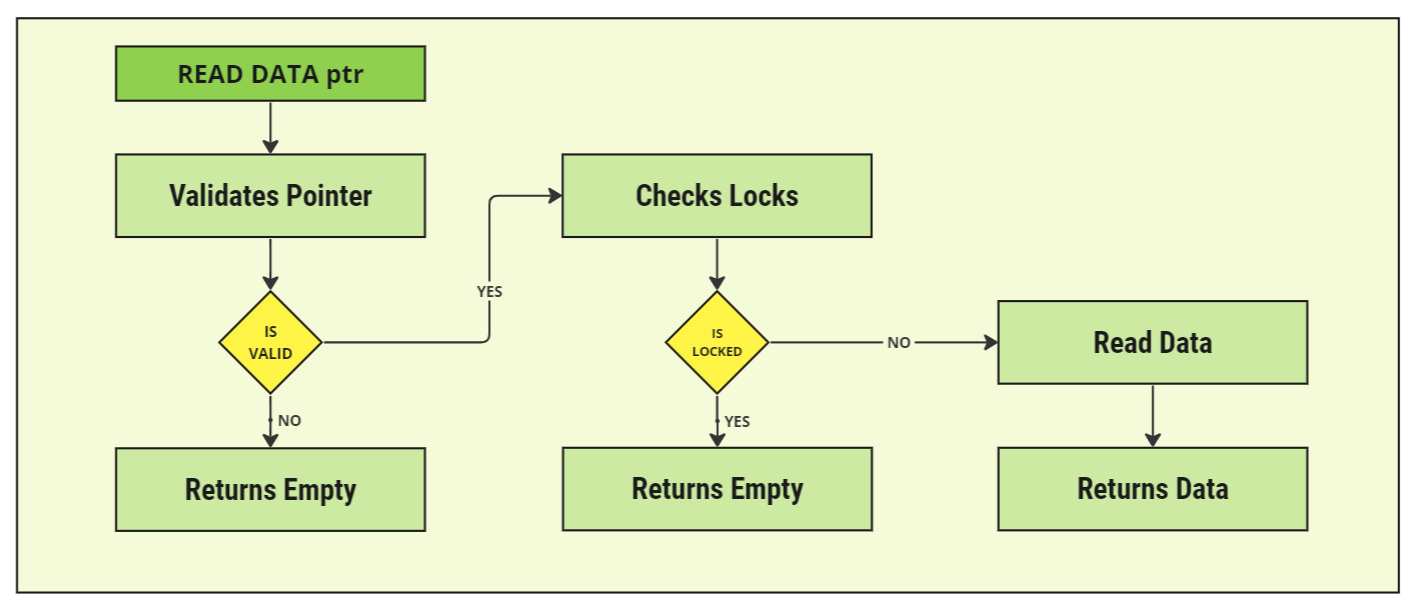
- Validates Pointer: The system validates that the pointer entered is valid; checks against the chunk size, the partition and the number of bytes required. The system will have no way of knowing if the pointer is wrong but still valid within the parameters so the pointer needs to remain correct otherwise invalid data will be returned.
- Checks Locked: The clusters can be locked up if there are errors or if a component model has been added to do so. If so, no byte data will be returned from the cluster.
- Reads Data: Once validated, the data will be retrieved from the storage system and returned to the user as a list of bytes.
Although the two above examples explain how to read and write binary byte data, the storage system is able to convert messages and objects into data and recompile them back to their original form. In all cases, a data pointer is returned that stores a reference to where the data is located within the storage system.
A data storage manager is able to connect to the data system and be able to store lists of messages and handles the direct interface to the data storage for handling reading and writing pointer data. This makes it easier for the user to track data and retrieve messages of a specific type. The partitioned data storage unit will only track the raw byte data and reference it with pointers.
Assumptions/Limitations
- Chunks are fixed and the size of each chunk must be the same between chunks.
- Every new chunk that is created will allocate bytes into RAM memory, where is the size of the chunk. Empty chunks will not be loading byte data into memory.